TL;DR: it’s easy using Seagate’s openSeaChest utility. Jump down to How to do the reformat using openSeaChest_Format below for the guide.
I recently purchased a pair of 20TB hard drives to replace the array of 8TB drives from almost 4 years ago (one of which had failed last year, and had been replaced under warranty). The 4×8TB array uses as much as 34 watts in random read and idles at 20 watts. The new 2×20TB would use about 13.8 watts when active, and 7.6 watts idle.
A ZFS mirror would provide ~20TB usable capacity — an increase of 4TB along with a power consumption savings of up to 59%.
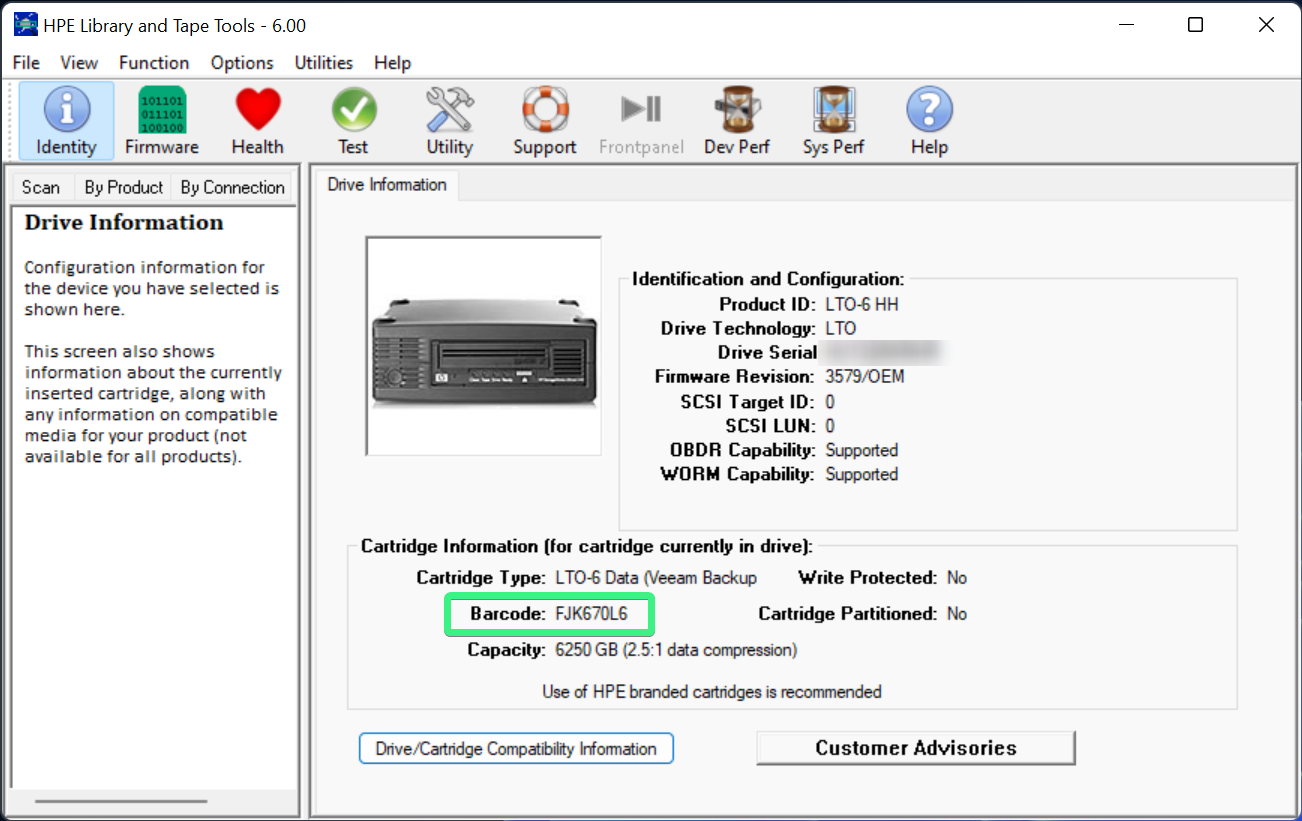
The only wrinkle was that these drives, unlike Seagate’s, are advertised only as 512e drives that emulate a 512-byte sector size, without any advertised capability to reformat in 4Kn. Many newer Seagate Exos drives have this capability built in (advertised as “FastFormat (512e/4Kn)”), whereas interestingly WD’s spec sheets for Red Pro drives no longer mention the sector size.
This distinction between using emulated 512e and native 4K sector size doesn’t make much of a practical difference in 2022 in storage arrays, because ZFS typically writes larger blocks than that. But I still wanted to see whether I could.
FastFormat using Seagate’s openSeaChest
Usually it is a bad idea to use one vendor’s tools with another’s. There were a lot of forum posts suggesting that the right utility is a proprietary WD tool called “HUGO,” which is not published on any WD support site. Somebody made a tool for doing this on Windows too: https://github.com/pig1800/WD4kConverter .
But I am using these WD Red Pros in a NAS enclosure running Linux, not Windows.
Seagate has one of the leading cross-platform utilities for SATA/SAS drive configuration: SeaChest. I think I’ve even been able to run one of these on ESXi through the Linux compatibility layer. Seagate publishes an open-source repository for the code under the name openSeaChest, available on GitHub: https://github.com/Seagate/openSeaChest , and thanks to the license, vendors like TrueNAS are able to include compiled executables of openSeaChest on TrueNAS SCALE.
openSeaChest includes a utility called openSeaChest_Format (sometimes compiled with the executable name openSeaChest_FormatUnit):
# openSeaChest_FormatUnit --help
==========================================================================================
openSeaChest_Format - openSeaChest drive utilities - NVMe Enabled
Copyright (c) 2014-2022 Seagate Technology LLC and/or its Affiliates, All Rights Reserved
openSeaChest_Format Version: 2.2.1-2_2_1 X86_64
Build Date: Sep 26 2022
Today: Sun Dec 4 13:49:42 2022 User: root
==========================================================================================
Usage
=====
openSeaChest_Format [-d <sg_device>] {arguments} {options}
Examples
========
openSeaChest_Format --scan
openSeaChest_Format -d /dev/sg? -i
*** excerpted ***
--setSectorSize [new sector size]
This option is only available for drives that support sector
size changes. On SATA Drives, the set sector configuration
command must be supported. On SAS Drives, fast format must
be supported. A format unit can be used instead of this
option to perform a long format and adjust sector size.
Use the --showSupportedFormats option to see the sector
sizes the drive reports supporting. If this option
doesn't list anything, please consult your product manual.
This option should be used to quickly change between 5xxe and
4xxx sector sizes. Using this option to change from 512 to 520
or similar is not recommended at this time due to limited drive
support
WARNING: Set sector size may affect all LUNs/namespaces for devices
with multiple logical units or namespaces.
WARNING (SATA): Do not interrupt this operation once it has started or
it may cause the drive to become unusable. Stop all possible background
activity that would attempt to communicate with the device while this
operation is in progress
WARNING: It is not recommended to do this on USB as not
all USB adapters can handle a 4k sector size.
I had a feeling openSeaChest could be used for my purposes, based on this information on StackExchange, indicating that the WD drives use ATA standards-defined “Set Sector Configuration Ext (B2h)” and “Sector Configuration Log.” Since that user was able to effect the reformat on a WD Ultrastar DC 14TB drive using camcontrol on FreeBSD, that was a good sign that the reformat should be possible. After all, the larger WD Red Pro drives are basically rebadged/binned Ultrastar drives.
This was confirmed later using openSeaChest_Format , but I also saw an encouraging sign in the drive info shown by openSeaChest_SMART -d /dev/sdX --SATInfo:
# openSeaChest_SMART -d /dev/sdf --SATInfo
*** excerpted ***
ATA Reported Information:
Model Number: WDC WD201KFGX-68BKJN0
Serial Number: REDACTEDSERIAL
Firmware Revision: 83.00A83
World Wide Name: REDACTEDSERIAL
Drive Capacity (TB/TiB): 20.00/18.19
Native Drive Capacity (TB/TiB): 20.00/18.19
Temperature Data:
Current Temperature (C): 44
Highest Temperature (C): 45
Lowest Temperature (C): 24
Power On Time: 3 days 15 hours
Power On Hours: 87.00
MaxLBA: 39063650303
Native MaxLBA: 39063650303
Logical Sector Size (B): 512
Physical Sector Size (B): 4096
Sector Alignment: 0
Rotation Rate (RPM): 7200
Form Factor: 3.5"
Last DST information:
DST has never been run
Long Drive Self Test Time: 1 day 12 hours 6 minutes
Interface speed:
Max Speed (Gb/s): 6.0
Negotiated Speed (Gb/s): 6.0
Annualized Workload Rate (TB/yr): 7437.88
Total Bytes Read (TB): 33.87
Total Bytes Written (TB): 40.00
Encryption Support: Not Supported
Cache Size (MiB): 512.00
Read Look-Ahead: Enabled
Write Cache: Enabled
SMART Status: Unknown or Not Supported
ATA Security Information: Supported
Firmware Download Support: Full, Segmented, Deferred, DMA
Specifications Supported:
ACS-5
ACS-4
ACS-3
ACS-2
ATA8-ACS
ATA/ATAPI-7
ATA/ATAPI-6
ATA/ATAPI-5
ATA/ATAPI-4
ATA-3
ATA-2
SATA 3.5
SATA 3.4
SATA 3.3
SATA 3.2
SATA 3.1
SATA 3.0
SATA 2.6
SATA 2.5
SATA II: Extensions
SATA 1.0a
ATA8-AST
Features Supported:
Sanitize
SATA NCQ
SATA NCQ Streaming
SATA Rebuild Assist
SATA Software Settings Preservation [Enabled]
SATA In-Order Data Delivery
SATA Device Initiated Power Management
HPA
Power Management
Security
SMART [Enabled]
DCO
48bit Address
PUIS
APM [Enabled]
GPL
Streaming
SMART Self-Test
SMART Error Logging
EPC
Sense Data Reporting [Enabled]
SCT Write Same
SCT Error Recovery Control
SCT Feature Control
SCT Data Tables
Host Logging
Set Sector Configuration
Storage Element Depopulation
Drive information before the reformat
The WD201KFGX drive comes formatted in 512e by default.
openSeaChest is able to discover the drive’s capability to support 4096 sector sizes using the --showSupportedFormats flag.
# openSeaChest_FormatUnit -d /dev/sdf --showSupportedFormats
*** excerpted ***
/dev/sg6 - WDC WD201KFGX-68BKJN0 - REDACTEDSERIAL - ATA
Supported Logical Block Sizes and Protection Types:
---------------------------------------------------
* - current device format
PI Key:
Y - protection type supported at specified block size
N - protection type not supported at specified block size
? - unable to determine support for protection type at specified block size
Relative performance key:
N/A - relative performance not available.
Best
Better
Good
Degraded
--------------------------------------------------------------------------------
Logical Block Size PI-0 PI-1 PI-2 PI-3 Relative Performance Metadata Size
--------------------------------------------------------------------------------
4096 Y N N N N/A N/A
4160 Y N N N N/A N/A
4224 Y N N N N/A N/A
* 512 Y N N N N/A N/A
520 Y N N N N/A N/A
528 Y N N N N/A N/A
--------------------------------------------------------------------------------
The command you want is --setSectorSize 4096
An example of this command is shown below, but you need to manually add --confirm this-will-erase-data to actually make it happen.
You must be certain you are acting on the correct drive! Use openSeaChest_Info -s to identify all connected drives.
To add just a tiny bit of friction to prevent drive-by readers from simply copying-and-pasting this command without thought, potentially wiping out the contents of their hard drive, I’m excluding it in the line below so you need to add it yourself. You also need to specify the correct drive instead of sdX.
# openSeaChest_FormatUnit -d /dev/sdX --setSectorSize 4096 --poll
In my example, it took only a few seconds, and the command provided confirmation that it was successful. Depending on your selected level of verbosity (-v [0-4]) you may see more detail about the ATA commands issued.
*** excerpted ***
Setting the drive sector size quickly.
Please wait a few minutes for this command to complete.
It should complete in under 5 minutes, but interrupting it may make
the drive unusable or require performing this command again!!
*** excerpted ***
Command Time (ms): 499.89
Set Sector Configuration Ext returning: SUCCESS
Successfully set sector size to 4096
After the instant reformat of the sector size, it is critical that you unplug and reinsert the hard drive to reinitialize it in the new format.
Drive information after the reformat
openSeaChest_SMART -d /dev/sdX --SATInfo shows this information:
*** excerpted ***
ATA Reported Information:
Model Number: WDC WD201KFGX-68BKJN0
Serial Number: REDACTEDSERIAL
Firmware Revision: 83.00A83
World Wide Name: REDACTEDSERIAL
Drive Capacity (TB/TiB): 20.00/18.19
Native Drive Capacity (TB/TiB): 20.00/18.19
Temperature Data:
Current Temperature (C): 41
Highest Temperature (C): 45
Lowest Temperature (C): 24
Power On Time: 3 days 17 hours
Power On Hours: 89.00
MaxLBA: 4882956287
Native MaxLBA: 4882956287
Logical Sector Size (B): 4096
Physical Sector Size (B): 4096
And hdparm -I /dev/sdX confirms:
*** excerpted ***
ATA device, with non-removable media
Model Number: WDC WD201KFGX-68BKJN0
Serial Number: REDACTEDSERIAL
Firmware Revision: 83.00A83
Transport: Serial, ATA8-AST, SATA 1.0a, SATA II Extensions, SATA Rev 2.5, SATA Rev 2.6, SATA Rev 3.0
Standards:
Supported: 12 11 10 9 8 7 6 5
Likely used: 12
Configuration:
Logical max current
cylinders 16383 16383
heads 16 16
sectors/track 63 63
--
CHS current addressable sectors: 16514064
LBA user addressable sectors: 268435455
LBA48 user addressable sectors: 4882956288
Logical Sector size: 4096 bytes [ Supported: 2048 256 ]
Physical Sector size: 4096 bytes
device size with M = 1024*1024: 19074048 MBytes
device size with M = 1000*1000: 20000588 MBytes (20000 GB)
cache/buffer size = unknown
Form Factor: 3.5 inch
Nominal Media Rotation Rate: 7200
Success! Let me know if this worked for you, and what model of hard drive it worked on.