
Update (2015-10-21): since the images below have not been updated since July 2014, I highly recommend that you no longer use them; instead, you should use a kickstart script to install from the latest packages. Also, as I’ve noted in the comments, PVHVM will likely perform better overall. Update (2017-04-28): the .xva files have now been deleted; instead see this new guide for converting .qcow2 cloud images for use with XenServer.
One of the most frequently visited blog posts on my site is a guide to installing paravirtualized Fedora 20 on XenServer using an automated kickstart file. With the recent releases of RedHat Enterprise Linux 7 (and the corresponding CentOS 7 — versioned at 7.0.1406) and Ubuntu 14.04 LTS “Trusty Tahr”, as well as prerelease versions of the next iteration of XenServer, I thought it was time to revisit this matter and show you the scripts for optimized paravirtualized guests running the newest versions of CentOS and Ubuntu.
Table of Contents
- Prebuilt images
- OpenStack gripes
- XenServer version differences
- Kickstart scripts
- Installation instructions
Prebuilt images for the lazy
If you’re lazy, you can skip the process and download prebuilt XenServer images that you can decompress (xz -d ___.xvz.xz or use your GUI of choice) then import through XenCenter (File – Import…) or the command line (xe vm-import filename=___.xva). These images do not have XenServer Tools installed, because you should install them yourself using the tools that match your XenServer version.
These images are provided with no guarantees. Please let me know (comments below are fine) if you find an issue with them.
- CentOS 7.0.1406 (as of 2014-07-16)
Filename:centos-7.0.1406-20140716-template.xva.xz
Size:322 MB xz-compressed; 1.6 GB decompressed
Specs:2 vCPUs, 2 GB RAM, 8 GB disk without swap, installed software
SHA256 hash:ab69ee14476120f88ac2f404d7584ebb29f9b38bdf624f1ae123bb45a9f1ed94
MD5 hash:91e3ce39790b0251f1a1fdfec2d9bef0
Username:centos
Password:Asdfqwerty - Ubuntu 14.04 LTS (as of 2014-07-16)
Filename:ubuntu-14.04-20140716-template.xva.xz
Size:549 MB xz-compressed; 1.9 GB decompressed
Specs:2 vCPUs, 2 GB RAM, 8 GB disk including 1 GB swap, installed software
SHA256 hash:1c691324d4e851df9131b6d3e4a081da3a6aee35959ed3defc7f831ead9b40f2
MD5 hash:e2ed6cfb629f916b9af047a05f8a192d
Username:ubuntu
Password:Asdfqwerty
Side note on OpenStack
It’s true that private cloud IaaS tools like OpenStack have been growing in popularity, and increasingly, vendors are distributing cloud images suitable for OpenStack (see Fedora Cloud images). My instructions in the rest of this blog post won’t help you build images for an IaaS platform. You might as well just get the vendor cloud images if you’re going to be using OpenStack.
You can skip down to the next heading if you don’t want to read about my experiences with OpenStack.
OpenStack isn’t right for everyone
I tested out OpenStack + KVM on an HP baremetal server with 12 physical cores and 48 GB of RAM recently. Despite the simplified installation process enabled by RedHat, it didn’t fit my needs, and I went back to using XenServer. OpenStack was a mismatch for my needs and also has a few infrastructural problems, and hopefully someone reading this will be able to tell me if I’m out of my mind or if these are actually legitimate concerns:
- Size of deployment. Even though it can be used on a single baremetal server, OpenStack is optimal for deployments involving larger private clouds with many servers. When working with a single host, the complexity wasn’t worth my time. This is where admins need to judge whether they fall on the virtualization side or the cloud side of a very blurry line.
- Complex networking. Networking in OpenStack using Neutron follows an EC2 model with floating IPs, though there are various “flat” options that will more simply bridge virtual networks. The floating IP model is poorly suited to situations when the public Internet-routable network has an existing external DHCP infrastructure, and no IPs or IP ranges can be reserved.
- Abstraction. From what I could tell, there were ridiculous levels of abstraction. On a single-host node that hosts the block storage service (Cinder) as well as the virtualization host (Nova), an LVM logical volume created by Cinder would be shared as an iSCSI target, mounted by the same machine, and only then exposed to qemu-kvm by the Nova compute service.
- Resource overhead. The way that packstack deployed the software on a CentOS 7 server placed OpenStack—compute service (Nova), block storage (Cinder), object storage (Swift), image storage (Glance), networking (Neutron), identity service (Keystone), and control panel (Horizon)—and all its dependency components—MariaDB, RabbitMQ, memcache, Apache httpd, KVM hypervisor, Open vSwitch, and whatever else I’m forgetting—on the nonvirtualized baremetal operating system. That’s a ton of services, and attack surface, for the host… And the worst part: because each of those programs realized that the server has 48 GB of physical RAM, they all helped themselves to as much as they could grab. MariaDB was configured automatically with huge memory buffers; RabbitMQ seemed to claim more than 3 GB of virtual memory. By the time any virtual guests had been started up, the baremetal system was reporting at least 7-9 GB of used RAM!
That’s when I had enough. Technical benefits of KVM aside, and management capabilities of OpenStack aside, I decided to move firmly back into virtualization territory. XenServer’s minimal dom0 design and light overhead was much more suitable for my needs.
Note your XenServer version
XenServer Creedence requires no fixes
XenServer Creedence alpha 4—the most recent prerelease version that I am using—uses a newer Xen hypervisor and bundled tools. Consequently, it seems to have a patched version of pygrub that can read the CentOS 7 grub.cfg, which uses the keywords linux16 and initrd16, and which is no longer affected by the same parsing bugs on default="${next_entry}" that necessitated the fixes at the end of the post-installation script.
Fixes needed by XenServer 6.2
However, XenServer 6.2 cannot handle the out-of-box installation (ext4 /boot partition, GPT, etc) under paravirtualization without additional customization. Kickstart scripts are still the easiest way to ensure that the guests are bootable out of the box, by predefining a working partition scheme, selecting a minimal package set, fixing the bootloader script, and generalizing the installation.
Additionally, XenServer 6.2 lacks a compatible built-in template for Ubuntu 14.04. Thus, it cannot use netboot to install 14.04; you must use the 14.04 server ISO image to install.
The scripts to do it yourself
CentOS 7
I determined that the true minimal @core installation is too minimal for typical needs (it doesn’t come with bind-utils, lsof, zip, etc) so this image is installed with the @base group. About 456 packages are included.
[github file=”/frederickding/xenserver-kickstart/blob/develop/centos-7.0/cent70-server.ks”]
Ubuntu 14.04:
[github file=”/frederickding/xenserver-kickstart/blob/develop/ubuntu-14.04/trusty-server.ks”]
The process to do it yourself
CentOS 7
- Use the CentOS 6 template for a baseline.
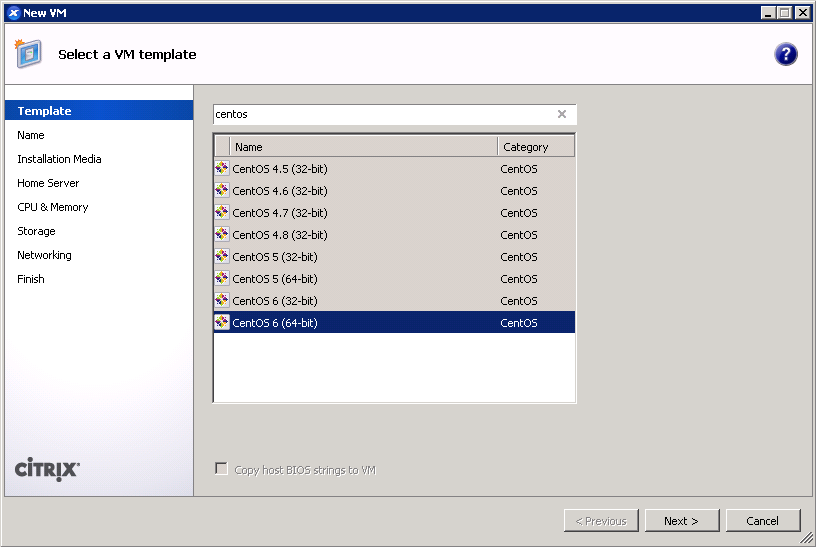
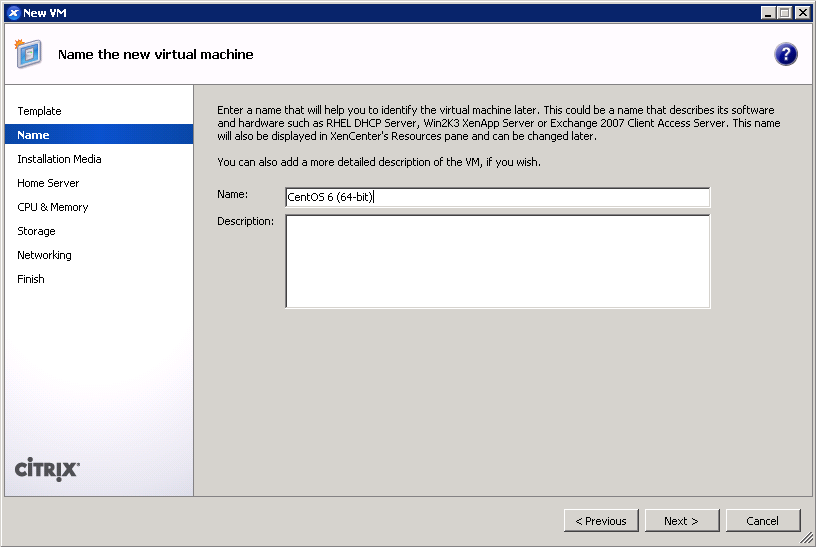
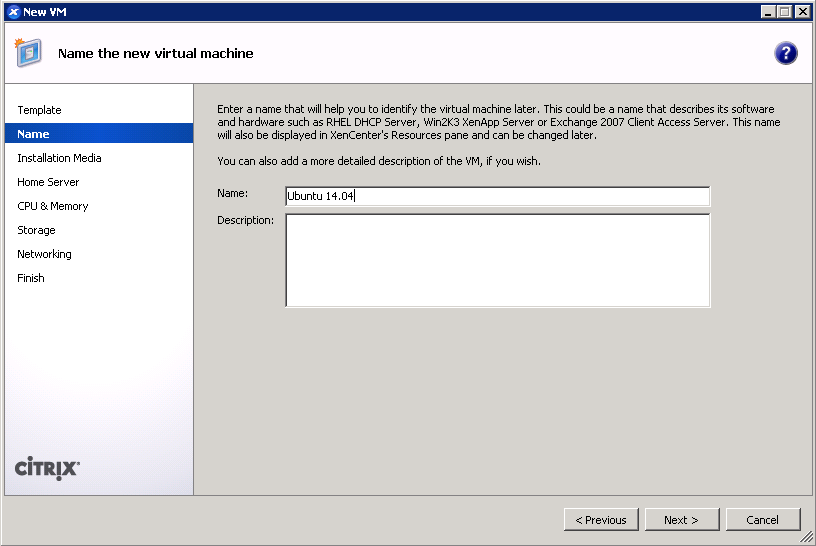
- Give your VM a name. (screenshot)
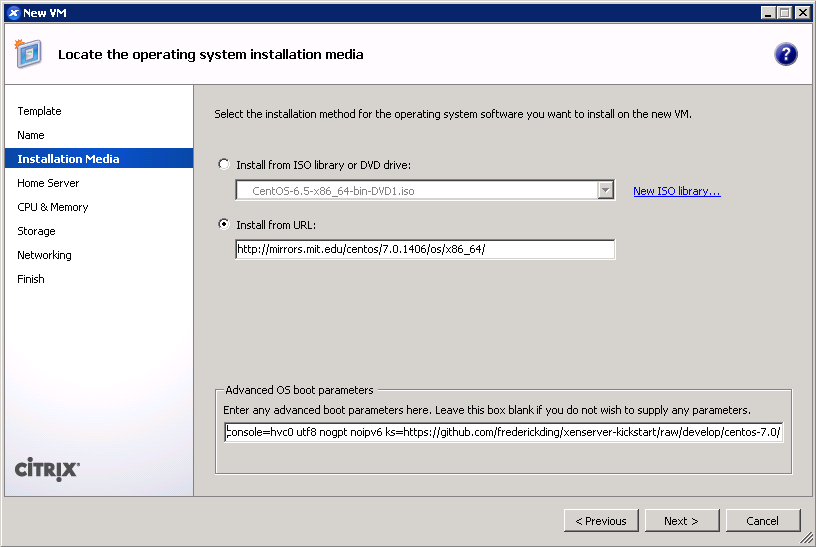
- IMPORTANT: Boot up a CentOS 7 installer with parameters. You can use the netboot ISO, or boot directly from an HTTP mirror (e.g. http://mirror.rackspace.com/CentOS/7.0.1406/os/x86_64/). This is also the screen where you specify the boot parameters:
console=hvc0 utf8 nogpt noipv6 ks=https://github.com/frederickding/xenserver-kickstart/raw/develop/centos-7.0/cent70-server.ks
Note: you may have to host the kickstart script on your own HTTP server, since occasional issues, possibly SSL-related, have been observed with netboot installers being unable to fetch the raw file through GitHub.
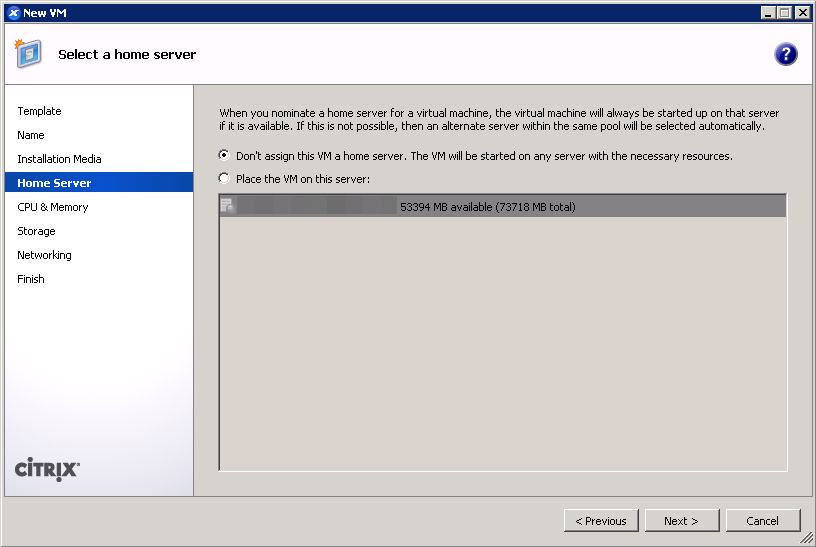
- Set a host server. (screenshot)
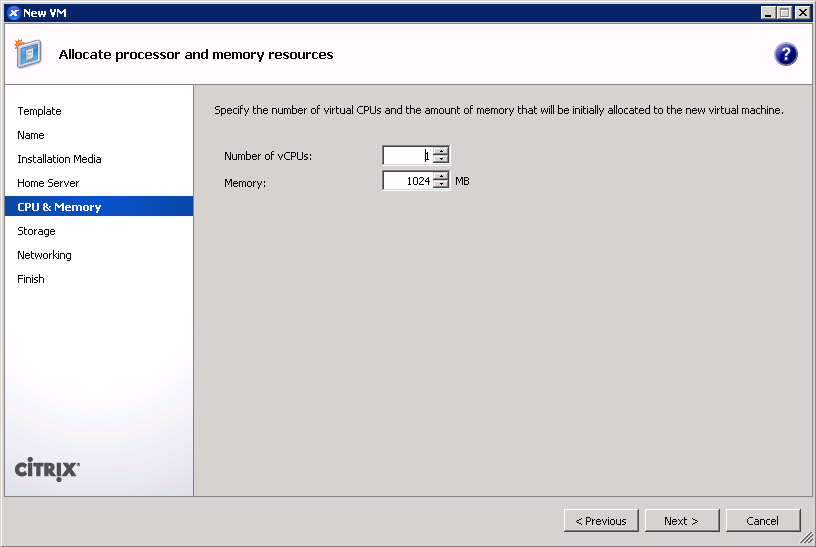
- Assign vCPUs and RAM; Anaconda demands around 1 GB of memory when no swap partition is defined. (screenshot)
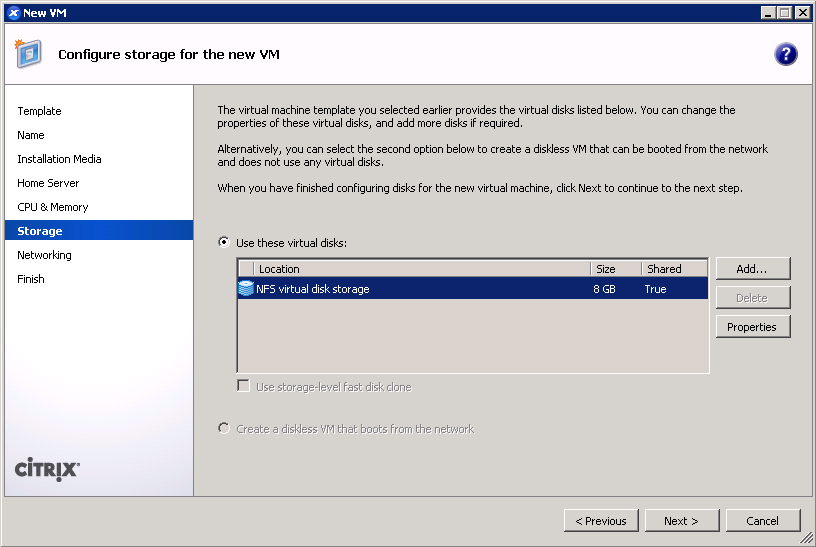
- Create a primary disk for the guest. Realistically, you need only 1-2 GB for the base installation, but XenServer may force you to set a minimum of 8 GB. No matter what size you set here, the kickstart script will make the root partition fill the free space. (screenshot)
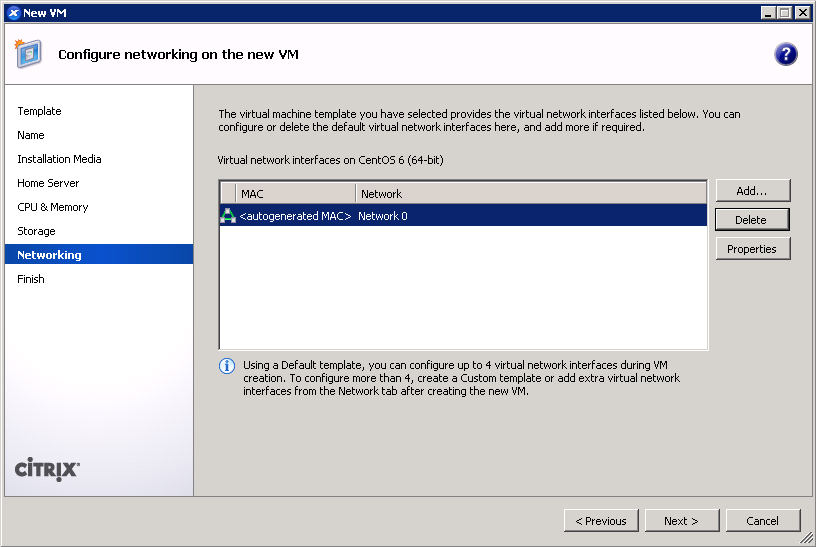
- IMPORTANT: Configure networking for the guest. It’s critical that this works out of the box (i.e. DHCP), since the script asks Anaconda to download packages from the HTTP repositories. (screenshot)
- Finish the wizard and boot up the VM.
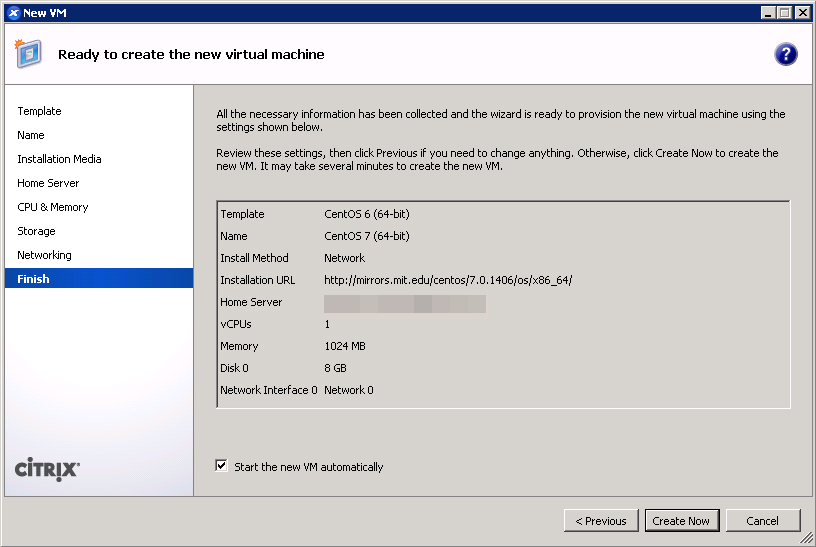
- The VM will boot into the CentOS 7 installer, which will run without interaction until it completes.
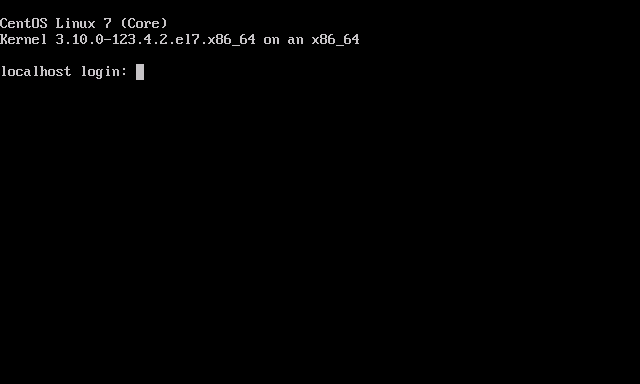
- Press <Enter> to halt the machine. At this point, you can remove the ISO (if any).
- Boot up the VM. It should go right into the login screen on the command line — from which you can do further configuration as needed.
Ubuntu 14.04
As mentioned above, this process will differ slightly if you are on XenServer 6.2 or older.
- On XenServer Creedence: Use the Ubuntu 14.04 template.
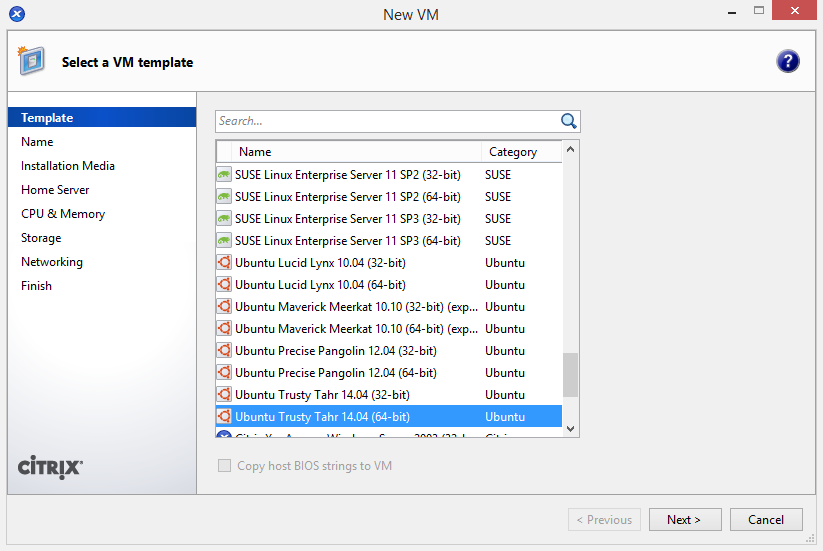 On XenServer 6.2 or older: Use the Ubuntu 12.04 template for a baseline.
On XenServer 6.2 or older: Use the Ubuntu 12.04 template for a baseline.
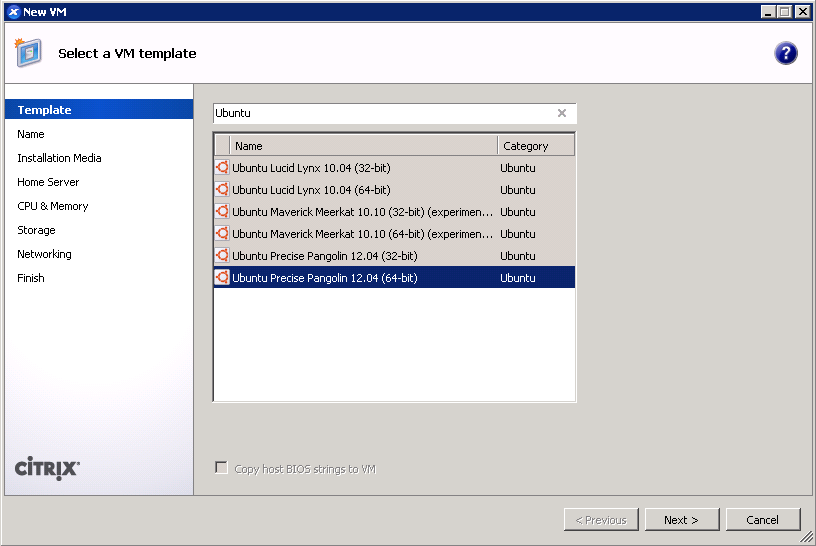
- Give your VM a name. (screenshot)
- IMPORTANT: On any version of XenServer: Boot up the 14.04 server ISO installer with parameters. You cannot use the netboot ISO.
On XenServer Creedence only: You can boot from an HTTP mirror, such as http://us.archive.ubuntu.com/ubuntu/.
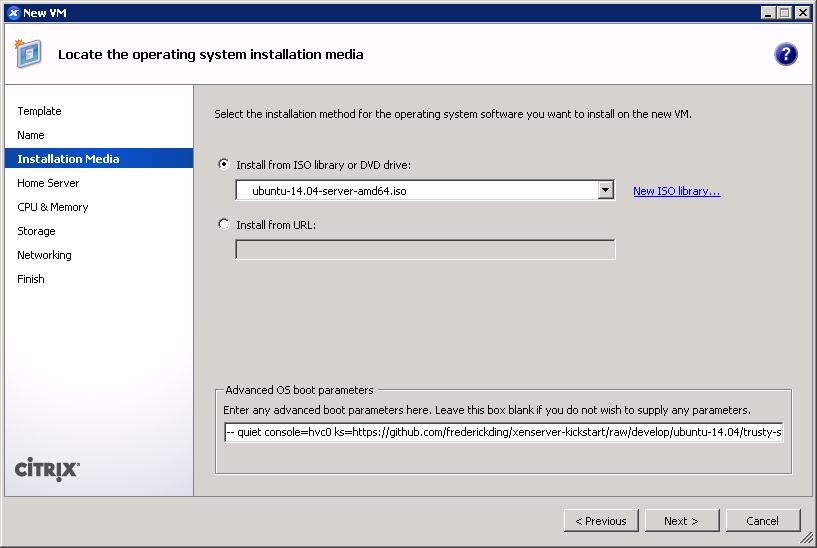 This is also the screen where you specify the boot parameters: append
This is also the screen where you specify the boot parameters: append ks=https://github.com/frederickding/xenserver-kickstart/raw/develop/ubuntu-14.04/trusty-server.ksto the existing parameters line.
Note: you may have to host the kickstart script on your own HTTP server, since issues, possibly SSL-related, have been observed with netboot installers being unable to fetch the raw file through GitHub. - Set a host server.
- Assign vCPUs and RAM.
- Create a primary disk for the guest. Realistically, you need only about 2 GB for the base installation, but XenServer may force you to set a minimum of 8 GB. No matter what size you set here, the kickstart script will make the root partition fill the free space.
- IMPORTANT: Configure networking for the guest. It’s critical that this works out of the box (i.e. DHCP), since the script asks the installer to download packages from online repositories.
- Finish the wizard and boot up the VM.
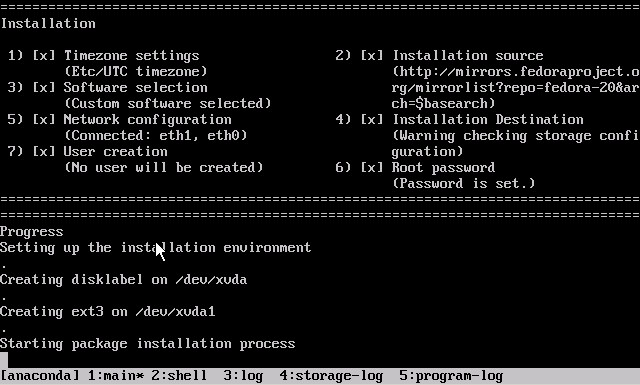
- The VM will boot into the Ubuntu installer, which will run without interaction until it completes.
Note: if you are warned that Grub is not being installed, you should nevertheless safely proceed with installation.
- Press <Enter> to halt the machine. At this point, you can remove the ISO (if any).
- Boot up the VM. It should go right into the login screen on the command line — from which you can do further configuration as needed, such as installing XenServer Tools.
Final thoughts
I recognize that these instructions require the use of a Windows program—XenCenter. I have not tried to conduct this installation using command line tools only. If you are a users without access to a Windows machine from which to run XenCenter, you can nevertheless deploy the kickstart-built XVA images above using nothing more than 2 or 3 commands on the dom0. If anyone can come up with a process to run through a kickstart-scripted installation using the xe shell tools, please feel free to share in the comments below.
I hope this has helped! I welcome your feedback.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}